As applications grow and data volumes explode, database performance inevitably becomes a critical bottleneck that can make or break user experience and business operations. While vertical scaling (adding more powerful hardware) provides temporary relief, sophisticated applications eventually require horizontal scaling strategies that can handle millions of records and thousands of concurrent users without performance degradation.
Database sharding and partitioning represent two fundamental approaches to database scaling, each offering distinct advantages for different scenarios and application architectures. Understanding when and how to implement these strategies can mean the difference between a scalable, high-performance application and one that struggles under load. This comprehensive guide explores both approaches, providing practical implementation strategies for PostgreSQL and MySQL environments.
Understanding Database Partitioning: Divide and Conquer Within a Single Database
What is Database Partitioning?
Database partitioning involves dividing large tables into smaller, more manageable pieces called partitions while maintaining them within a single database instance. This approach improves query performance by allowing the database engine to scan only relevant partitions rather than entire tables, dramatically reducing I/O operations and query execution times for large datasets.
Partitioning operates transparently to applications—queries continue to target the original table while the database engine automatically routes operations to appropriate partitions. This transparency makes partitioning an attractive scaling solution that requires minimal application code changes while providing significant performance improvements.
Horizontal Partitioning (Most Common): Data is distributed across partitions based on specific criteria, with each partition containing a subset of rows. For example, customer data might be partitioned by registration date, with each partition containing customers from specific time periods.
Vertical Partitioning: Columns are distributed across partitions, with each partition containing a subset of table columns. This approach is useful for tables with many columns where queries typically access only specific column sets.
PostgreSQL Partitioning Implementation
PostgreSQL offers robust native partitioning capabilities that have evolved significantly in recent versions, providing enterprise-grade partitioning features with excellent performance characteristics.
Range Partitioning: Ideal for time-series data or sequential identifiers. PostgreSQL automatically routes queries to appropriate partitions based on partition constraints, dramatically improving query performance for date-range queries or sequential data access patterns.
-- Example: Partitioning orders table by date
CREATE TABLE orders (
order_id SERIAL,
customer_id INTEGER,
order_date DATE,
total_amount DECIMAL(10,2)
) PARTITION BY RANGE (order_date);
CREATE TABLE orders_2024_q1 PARTITION OF orders
FOR VALUES FROM ('2024-01-01') TO ('2024-04-01');
CREATE TABLE orders_2024_q2 PARTITION OF orders
FOR VALUES FROM ('2024-04-01') TO ('2024-07-01');
Hash Partitioning: Distributes data evenly across partitions using hash functions, ideal for uniformly distributing data when natural partitioning criteria aren’t obvious. This approach ensures balanced partition sizes while maintaining query performance.
List Partitioning: Assigns specific values to particular partitions, useful for categorical data or geographic distribution. This method provides precise control over data distribution while enabling partition pruning for category-specific queries.
MySQL Partitioning Strategies
MySQL’s partitioning implementation provides similar functionality with some syntax and feature differences compared to PostgreSQL. Understanding MySQL-specific partitioning nuances is crucial for optimal implementation.
Partition Pruning Optimization: MySQL’s query optimizer automatically eliminates irrelevant partitions from query execution plans, but proper partition key selection is critical for maximizing this benefit. Partition keys should align with common query patterns to ensure optimal partition pruning.
Storage Engine Considerations: MySQL partitioning works differently across storage engines. InnoDB partitioning provides full transactional support and foreign key compatibility, while MyISAM partitioning offers different performance characteristics suited to specific use cases.
-- MySQL range partitioning example
CREATE TABLE sales_data (
sale_id INT AUTO_INCREMENT,
sale_date DATE,
amount DECIMAL(10,2),
region VARCHAR(50),
PRIMARY KEY (sale_id, sale_date)
) PARTITION BY RANGE (YEAR(sale_date)) (
PARTITION p2022 VALUES LESS THAN (2023),
PARTITION p2023 VALUES LESS THAN (2024),
PARTITION p2024 VALUES LESS THAN (2025)
);
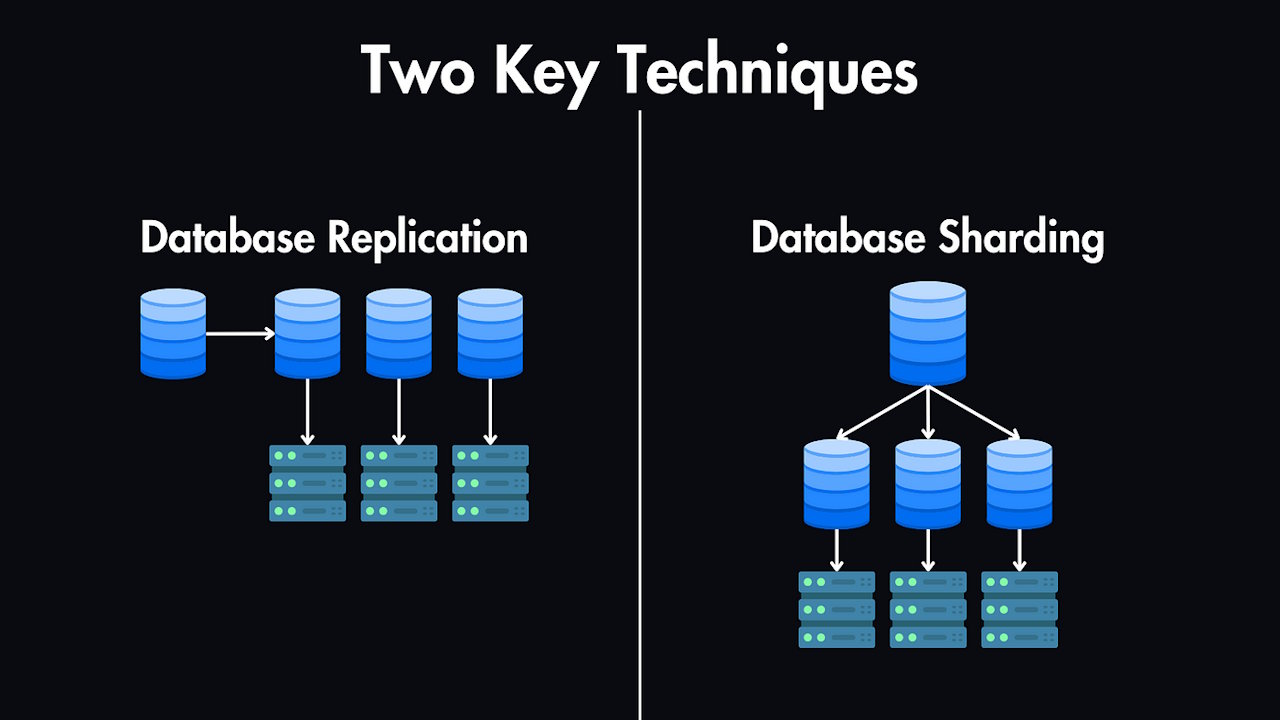
Database Sharding: Distributing Data Across Multiple Database Instances
Understanding Sharding Architecture
Database sharding distributes data across multiple separate database instances (shards), with each shard containing a subset of the total dataset. Unlike partitioning, sharding requires application-level logic to determine which shard contains specific data and route queries appropriately.
Sharding provides true horizontal scalability by distributing both data and computational load across multiple servers, enabling applications to scale beyond the limitations of single database instances. However, this scalability comes with increased architectural complexity and specific challenges that must be carefully managed.
Horizontal Sharding: The most common approach, where rows are distributed across shards based on sharding keys. Each shard contains the same table structure but different data subsets, enabling parallel processing and load distribution.
Vertical Sharding: Different tables or services are distributed across separate shards, often aligned with microservices architectures where each service manages its own data domain.
Sharding Key Selection and Distribution Strategies
The choice of sharding key fundamentally determines sharding effectiveness, data distribution, and query performance. Poor sharding key selection can result in uneven data distribution (hotspots) and complex cross-shard query requirements.
Hash-Based Sharding: Uses hash functions to distribute data evenly across shards. This approach provides good distribution balance but makes range queries challenging and complicates shard rebalancing when adding or removing shards.
Range-Based Sharding: Distributes data based on value ranges, such as customer ID ranges or geographic regions. This method enables efficient range queries but can result in uneven distribution if data patterns aren’t uniform.
Directory-Based Sharding: Uses a lookup service to map sharding keys to specific shards, providing maximum flexibility for data distribution but requiring additional infrastructure complexity and potential lookup service bottlenecks.
PostgreSQL Sharding Implementation Strategies
PostgreSQL’s federated table capabilities and connection pooling features provide excellent foundations for implementing sharding architectures, though most sharding logic requires application-level implementation.
Foreign Data Wrappers (FDW): PostgreSQL’s FDW functionality enables accessing remote databases as if they were local tables, providing a foundation for implementing distributed queries across shards while maintaining SQL compatibility.
Connection Pooling with PgBouncer: Efficient connection management becomes critical in sharded environments where applications must maintain connections to multiple database instances. PgBouncer provides connection pooling that reduces connection overhead and enables efficient resource utilization.
Logical Replication for Shard Management: PostgreSQL’s logical replication features enable sophisticated shard management strategies, including shard splitting, rebalancing, and hot migration of data between shards without downtime.
MySQL Sharding Architectures
MySQL sharding implementations often leverage proxy layers and middleware solutions that provide transparent sharding while maintaining MySQL protocol compatibility.
ProxySQL for Query Routing: ProxySQL provides sophisticated query routing capabilities that can implement sharding logic transparently to applications, including read/write splitting, query caching, and failover management.
MySQL Router Integration: MySQL Router provides native load balancing and connection routing capabilities that integrate seamlessly with MySQL Group Replication for high availability sharded environments.
Application-Level Sharding Libraries: Many applications implement sharding through database abstraction layers that handle shard routing, connection management, and cross-shard query coordination while maintaining code simplicity.
Performance Characteristics and Optimization Strategies
Query Performance Analysis
Understanding query performance implications helps determine when partitioning or sharding provides optimal benefits for specific workload patterns and data access requirements.
Partition Elimination Benefits: Well-designed partitioning schemes enable dramatic performance improvements through partition elimination, where queries scan only relevant partitions rather than entire tables. Time-based partitioning often provides 10x or greater performance improvements for date-range queries.
Parallel Query Execution: Both partitioning and sharding enable parallel query execution, though with different characteristics. Partitioning enables intra-query parallelism within single database instances, while sharding enables inter-query parallelism across multiple instances.
Index Optimization Strategies: Partitioned tables require careful index strategy consideration, as each partition maintains separate indexes. Local indexes provide partition-specific optimization, while global indexes (where supported) enable cross-partition uniqueness constraints.
Scalability Characteristics
Different scaling approaches provide distinct scalability characteristics that align with different application growth patterns and resource constraints.
Linear Scalability with Sharding: Properly implemented sharding can provide near-linear scalability by distributing both data and computational load across multiple servers. This approach enables applications to scale beyond single-server limitations.
Vertical Scaling Optimization: Partitioning optimizes single-server resource utilization, often enabling applications to handle significantly larger datasets and higher query volumes without requiring additional servers.
Resource Utilization Patterns: Sharding distributes resource utilization across multiple servers, while partitioning concentrates optimized resource usage within single instances. Understanding these patterns helps align scaling strategies with infrastructure capabilities and cost constraints.
When to Choose Partitioning vs. Sharding
Partitioning Use Cases and Benefits
Partitioning provides optimal benefits for specific scenarios where data access patterns align well with partition boundaries and single-server scaling remains viable.
Time-Series Data Management: Applications with time-based data access patterns benefit enormously from temporal partitioning. Log analysis systems, financial transaction processing, and IoT data collection often achieve dramatic performance improvements through date-based partitioning.
Data Lifecycle Management: Partitioning simplifies data archival and retention policies by enabling partition-level operations. Old partitions can be archived or dropped efficiently without affecting current data access patterns.
Query Performance Optimization: Applications with predictable query patterns that align with partition keys experience significant performance improvements through partition elimination and parallel processing capabilities.
Maintenance Window Reduction: Partitioned tables enable partition-level maintenance operations, reducing downtime for index rebuilding, statistics updates, and data consistency checks on large datasets.
Sharding Implementation Scenarios
Sharding becomes necessary when applications exceed single-server capabilities or require geographic data distribution that partitioning cannot provide.
High-Volume OLTP Applications: Applications with millions of concurrent users and massive transaction volumes often require sharding to distribute computational load across multiple servers while maintaining response time requirements.
Geographic Data Distribution: Multi-region applications benefit from geographic sharding that places data closer to users while complying with data sovereignty requirements and reducing network latency.
Microservices Architecture Alignment: Sharding aligns naturally with microservices architectures where different services manage distinct data domains, enabling service-specific scaling and technology choices.
Regulatory Compliance Requirements: Some compliance frameworks require data isolation that sharding provides more effectively than partitioning, particularly for multi-tenant applications with strict data separation requirements.
Implementation Challenges and Solutions
Partitioning Challenges
While partitioning provides significant benefits, several implementation challenges require careful consideration and planning.
Partition Key Selection: Choosing appropriate partition keys requires deep understanding of data access patterns and query requirements. Poor partition key selection can result in partition skew or ineffective partition elimination.
Cross-Partition Queries: Queries that span multiple partitions may experience performance degradation compared to single-partition queries. Application design should minimize cross-partition query requirements through careful data modeling.
Constraint Management: Unique constraints and foreign keys require special consideration in partitioned environments, as they may need to include partition keys or be implemented as application-level constraints.
Sharding Implementation Complexity
Sharding introduces architectural complexity that requires sophisticated solutions for distributed data management challenges.
Cross-Shard Transactions: Distributed transactions across multiple shards require careful coordination to maintain ACID properties. Many applications avoid cross-shard transactions through careful data modeling and eventual consistency patterns.
Data Rebalancing: Adding or removing shards requires data migration that must be handled carefully to avoid downtime and data consistency issues. Hot shard migration techniques enable rebalancing without service interruption.
Query Coordination: Cross-shard queries require application-level coordination to aggregate results from multiple shards, often involving map-reduce patterns or distributed query processing frameworks.
Operational Complexity: Managing multiple database instances increases operational overhead for monitoring, backup, security, and maintenance procedures that must be coordinated across all shards.
Monitoring and Maintenance Strategies
Performance Monitoring
Effective monitoring strategies are crucial for maintaining optimal performance in partitioned and sharded environments.
Partition-Level Metrics: Monitoring systems should track partition-specific metrics including query distribution, partition elimination effectiveness, and individual partition performance characteristics.
Shard Distribution Analysis: Sharded environments require monitoring of data distribution balance, query routing effectiveness, and individual shard performance to identify hotspots and optimization opportunities.
Query Pattern Analysis: Understanding evolving query patterns helps optimize partition schemes and sharding strategies over time, ensuring that scaling strategies remain aligned with application requirements.
Maintenance Automation
Automated maintenance procedures become increasingly important as database complexity grows through partitioning or sharding implementations.
Automated Partition Management: Scripts and procedures should automate partition creation, archival, and removal based on data lifecycle policies, reducing manual maintenance overhead and ensuring consistency.
Shard Health Monitoring: Automated health checks across all shards enable proactive identification of performance issues, capacity constraints, and failure conditions before they impact application performance.
Backup and Recovery Coordination: Distributed environments require coordinated backup and recovery procedures that maintain data consistency across partitions or shards while enabling point-in-time recovery capabilities.
Cost-Benefit Analysis and Planning
Resource Planning Considerations
Understanding resource implications helps make informed decisions about partitioning versus sharding implementations based on infrastructure capabilities and budget constraints.
Infrastructure Costs: Partitioning optimizes single-server utilization and may delay hardware upgrade requirements, while sharding requires multiple servers but can leverage commodity hardware for cost-effective scaling.
Operational Overhead: Partitioning generally requires less operational complexity than sharding, though both approaches require specialized expertise for optimal implementation and maintenance.
Development Complexity: Application code complexity increases more significantly with sharding than with partitioning, as sharding requires distributed data management logic while partitioning often operates transparently.
Performance ROI Analysis
Measuring return on investment helps justify scaling approach decisions and optimize implementation strategies for maximum business value.
Query Performance Improvements: Well-implemented partitioning often provides 5-10x performance improvements for appropriate query patterns, while sharding can provide linear scalability benefits that enable handling exponentially larger workloads.
Scalability Headroom: Partitioning provides scaling within single-server limits, while sharding provides virtually unlimited scaling potential at the cost of increased complexity and infrastructure requirements.
Maintenance Efficiency: Both approaches can dramatically reduce maintenance windows and improve data lifecycle management, providing operational benefits that translate into improved application availability and reduced administrative overhead.
Conclusion: Strategic Database Scaling for Modern Applications
The choice between database partitioning and sharding depends on specific application requirements, growth patterns, infrastructure constraints, and architectural preferences. Partitioning provides an excellent scaling solution for applications that can benefit from improved single-server performance, while sharding enables unlimited horizontal scaling for applications that have outgrown single-server capabilities.
Successful implementation of either approach requires careful planning, deep understanding of data access patterns, and ongoing optimization based on evolving application requirements. PostgreSQL and MySQL both provide robust capabilities for implementing sophisticated scaling strategies, though the specific implementation details and optimization techniques vary between platforms.
For applications experiencing performance challenges with growing datasets, implementing appropriate partitioning or sharding strategies can provide dramatic performance improvements while ensuring scalability for future growth. The key is understanding your specific requirements and choosing the approach that aligns with your application architecture, operational capabilities, and long-term scaling objectives.
Professional database scaling implementation requires expertise in both technical implementation and strategic planning to ensure optimal results that provide lasting value for growing applications and businesses.